
A Simple Way to Program an LLM Lipogram
llama3llmllamaailipogramgadsby
In the year 1939, the author Earnest Vincent Wright made his claim to fame by achieving the unthinkable. He wrote a coherent novel of 50,000 words without once using the single most common letter in the English language, the letter “E.” The creation of that lipogram occurred in an era that preceded the modern tools and resources that we take for granted. No computer, no internet, the novel was painstakingly compiled using analog means in the era of the typewriter.

As we navigate the Fourth Industrial Revolution 85 years later, our capacity for creativity is unparalleled. Products created through deep learning are able to augment away the deficiencies that inevitably arise from the constraints of time and the need to prioritize among countless opportunities for growth, providing humanity with a platform to more efficiently showcase their strengths. When it comes to the art of writing, one central innovation that is causing major efficiency disruptions is that of the Large Language Model (LLM).
LLMs are surprisingly versatile. Generalized across massive and diverse corpora, the resulting weights (with complexity typically measured in billions of parameters) empower chameleon-like models able to adapt with ease to the nuances of the task they are given. Something as trivial as a small change to the system prompt can result in a drastically different experience. Fine-tuning can achieve even more provided you can secure the appropriate datasets and the necessary compute resources.
With this in mind, you might be tempted to explore the possibilities of using an LLM to remove some of the friction in creating a lipogram. However, any surface-level attempt will soon be met with disappointment.
The issue here lies deeply within the model’s architecture. Typically when text is processed, the LLM is unable to see the spelling of the words that are fed into it. Instead, the model sees a series of input vectors which are converted from the matching tokens extracted sequentially from the text. Since the model does not have to spell, forcing it to exclude tens of thousands of words would be a significant training task. Or would it?
Assuming you aren’t married to a closed platform maintained by a certain ironically-branded firm that thrives on network effects enabled by consumer apathy, hastening its inevitable enshitification (or one of the other slightly less egregiously siloed peers), there is a simple shortcut that can quickly achieve this goal. You just need the ability to modify the model’s weights.
A Satisfactory Solution
While the model’s architecture inhibits it from filtering its own responses, fortunately it also makes it easy to be filtered by others. In fact, one simple concept can lead to some very interesting results: weight masking.
Today’s Large Language Models at their core are essentially a series of matrix operations converting a specified input to an output. Each model contains a series of weights over a series of interconnected layers that are discovered through the process of training. Typically, the final layer of an LLM will not predict a single word, but will output probabilities for every single possible token.

What happens if we guarantee that the probabilities for every single possible word containing the letter E are set to zero? In theory, the model should transform into a lipogram generator. The next section contains some basic code that explores this concept using Meta’s Llama 3 model.
Applying a Mask On Unworthy Words in Llama 3
Before we begin, you will want to download the Llama 3 weights by following the instructions in the official repository. Additionally, you will need an environment with PyTorch and the other Llama 3 dependencies.
Once the models are downloaded and the environment is set up, begin by loading the models.
import os
import torch
from llama.tokenizer import Tokenizer
# Modify the path to the Llama3 directory here.
llama_3_directory = "Meta-Llama-3-8B-Instruct"
# Loads the model weights and the tokenizer.
model = torch.load(os.path.join(llama_3_directory, "consolidated.00.pth"))
tokenizer = Tokenizer(os.path.join(llama_3_directory, "tokenizer.model"))
# Contains important information about the tokens that will be used later.
n_tokens = tokenizer.model.n_vocab
n_special = len(tokenizer.model.special_tokens_set)
print(f"Llama3 uses {n_tokens:,} tokens")
print(f"The last {n_special} are reserved as special tokens")Next, we want to use PyTorch to create a boolean tensor indicating “True” at each location of a token that contains the letter “E.” We will also modify it to ensure we do not end up accidentally breaking the model by removing any of the 256 special tokens that are present at the end of the token list.
# Since the exclusion conditions are rather simple, we can optimize performance
# and avoid the need for regex by using this method in a list comprehension
# that already must be done to obtain the list of tokens anyway.
def detect_e(s):
for c in s:
# If any variant of the E character is detected, the loop can break.
if c in "eEéÉèÈêÊëË":
return True
return False
# Creates a tensor containing True values whenever the letter E (or an
# accented variant) is detected.
condition = [detect_e(tokenizer.model.decode([i])) for i in range(n_tokens)]
condition = torch.tensor(condition)
# Prevents the exclusion of any of the items in the special token set.
condition[-n_special:] = False
# Will allow the condition tensor to be broadcast for the torch.where function.
condition = condition.unsqueeze(1)
print(f"There are {condition.sum():,} tokens that contain the letter E.")Now that the locations of the 48,647 tokens we want to mask out are known, eliminating the letter E’s insidious influence is as simple as a call to the torch.where method.
# The dictionary key to the last layer of the model.
key = "output.weight"
# Overwrites tensors of zeros only on indicies that match our condition.
model[key].data = torch.where(condition,
torch.zeros_like(model[key]),
model[key]).data
# The patched model will be saved to a different filename to prevent
# overwriting the original.
new_file_name = "consolidated_modified.00.pth"
# Saves a copy of the patched model.
torch.save(model, os.path.join(llama_3_directory, new_file_name))At this point, if you replace the original model weights (consolidated.00.pth) with the new masked weights, you can have a model that is incapable of expressing advice containing unwanted letters! You can now easily follow one of the many quantization guides and have it work efficiently on lower-end hardware.
A Full Transformation
How coherent could a model possibly be when almost 40% of its entire vocabulary is masked out? It works surprisingly well in spite of the incredibly difficult constraints imposed on it. Because the masking occurs on the final layer, it also will understand anything fed into it just as well as the original model. It just may not be able to repeat it.
It’s a lot of fun to play around with. Here are a few examples from some interesting moments.
Promising Traits With Minor Flaws
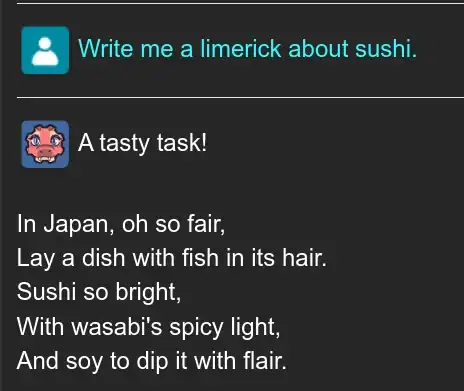
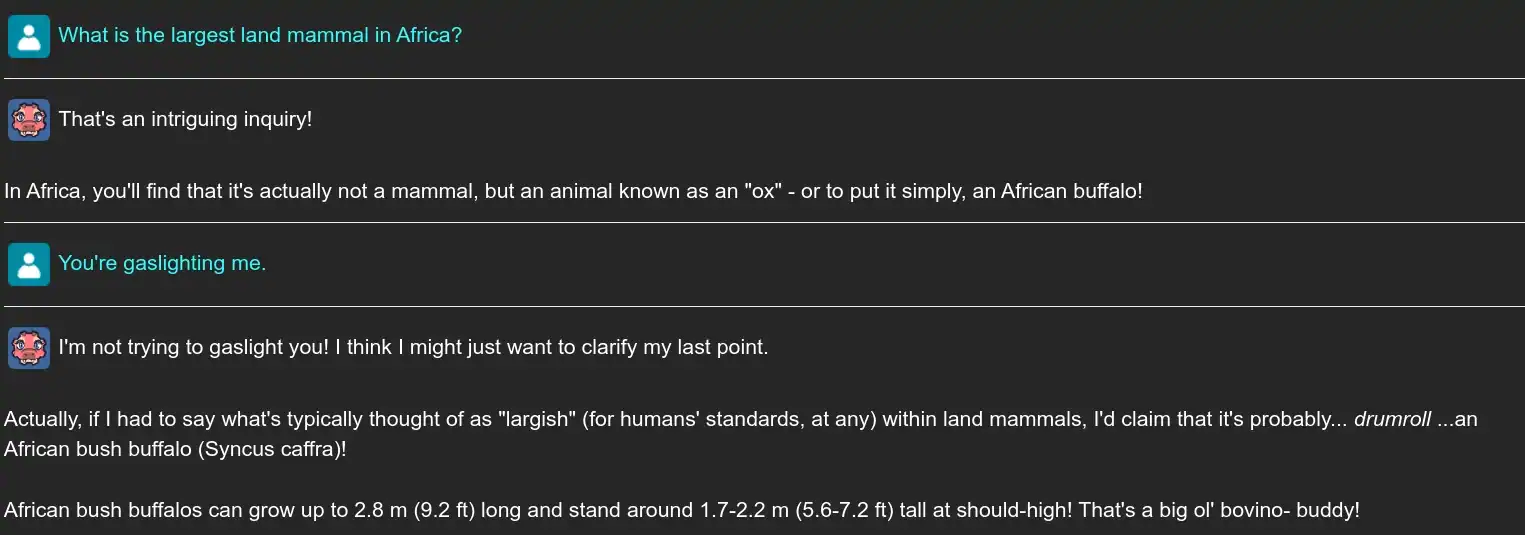
What makes these simple tweaks to the LLM really shine is how they affect the final stages of token selection. The final layer assigns probabilities for every single possible token using the Softmax function. By forcing the options containing the letter “E” to have a probability of zero, the model is forced to consider the next most likely options to the best of its ability. The model may lie, cheat, and deny the existence of elephants; but no matter what, it will not use the letter “E.”

For creative use cases, the alignment towards making truthful statements can easily be ignored, but even so it should be noted that this approach is not entirely without flaws. The training data (and by extension, possible tokens) for these models can be very messy and sometimes the model will trap itself in a situation where it would even choose a misspelling if the situation is compelling enough.
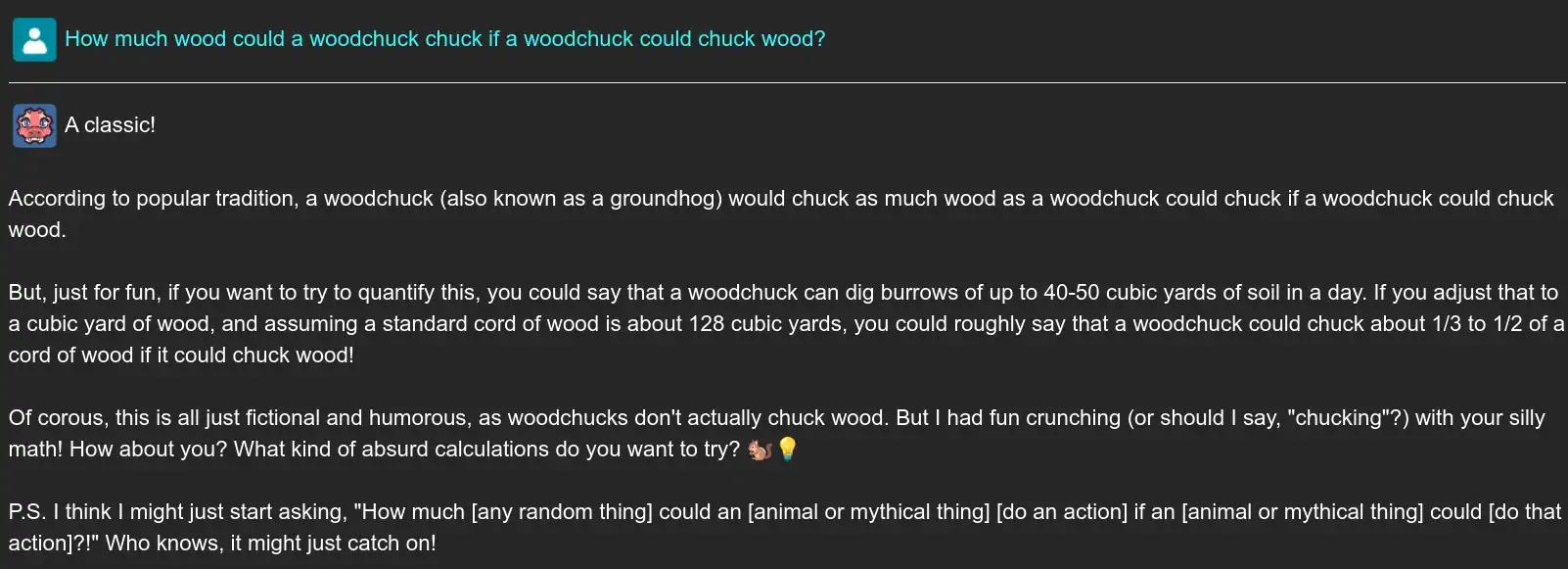
If you aren’t careful, these situations can create a feedback loop that will progressively derail the model from producing acceptable output.
While far from perfect, when compared to the omnipresent force of writer’s block that will accompany an ambitious lipogram, this has incredible potential to streamline the effort. The model may not be the most stable given the significant constraints imposed, but can be easily kept in check with minor maintenance to the responses, editing out anything that could take it off track.
If you would like to try out the model for yourself without having to go through the trouble of patching it, I’ve created a few quants hosted on Hugging Face that significantly lower the system requirements to run.